Law of total variance
In probability theory, the law of total variance[1], Eve's Law, or variance decomposition formula states that if X and Y are random variables on the same probability space, and the variance of Y is finite, then
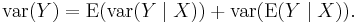
In language perhaps better known to statisticians than to probabilists, the two terms are the "unexplained" and the "explained component of the variance" (cf. fraction of variance unexplained, explained variation).
The nomenclature in this article's title parallels the phrase law of total probability. Some writers on probability call this the "conditional variance formula" or use other names.
Note that the conditional expected value E( Y | X ) is a random variable in its own right, whose value depends on the value of X. Notice that the conditional expected value of Y given the event X = y is a function of y (this is where adherence to the conventional rigidly case-sensitive notation of probability theory becomes important!). If we write E( Y | X = y ) = g(y) then the random variable E( Y | X ) is just g(X). Similar comments apply to the conditional variance.
Contents |
Proof
The law of total variance can be proved using the law of total expectation: First,
![\operatorname{Var}[Y] = \operatorname{E}[Y^2] - \operatorname{E}[Y]^2](/2012-wikipedia_en_all_nopic_01_2012/I/7511c7d172aea63ba30efb68466d3d7b.png)
from the definition of variance. Then we apply the law of total expectation by conditioning on the random variable X:
![= \operatorname{E}\left[\operatorname{E}[Y^2|X]\right] - \operatorname{E}\left[\operatorname{E}[Y|X]\right]^2](/2012-wikipedia_en_all_nopic_01_2012/I/a8cac676ca5f119b480ab79737ffb924.png)
Now we rewrite the conditional second moment of Y in terms of its variance and first moment:
![= \operatorname{E}\!\left[\operatorname{Var}[Y|X] %2B \operatorname{E}[Y|X]^2\right] - \operatorname{E}[\operatorname{E}[Y|X]]^2](/2012-wikipedia_en_all_nopic_01_2012/I/33a46e93ea36e92b6032099d20bf72a2.png)
Since expectation of a sum is the sum of expectations, we can now regroup the terms:
![= \operatorname{E}[\operatorname{Var}[Y|X]] %2B \left(\operatorname{E}\left[\operatorname{E}[Y|X]^2] - \operatorname{E}[\operatorname{E}[Y|X]\right]^2\right)](/2012-wikipedia_en_all_nopic_01_2012/I/040ef3f109813ff79ade2e9aadbb1a81.png)
Finally, we recognize the terms in parentheses as the variance of the conditional expectation E[Y|X]:
![= \operatorname{E}\left[\operatorname{Var}[Y|X]\right] %2B \operatorname{Var}\left[\operatorname{E}[Y|X]\right]](/2012-wikipedia_en_all_nopic_01_2012/I/e0b3d0ca785b1fcffac24a9c4b11156c.png)
The square of the correlation
In cases where (Y, X) are such that the conditional expected value is linear; i.e., in cases where
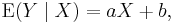
it follows from the bilinearity of Cov(-,-) that
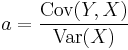
and
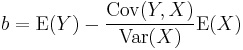
and the explained component of the variance divided by the total variance is just the square of the correlation between Y and X; i.e., in such cases,
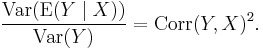
One example of this situation is when (Y, X) have a bivariate normal (Gaussian) distribution.
Higher moments
A similar law for the third central moment μ3 says
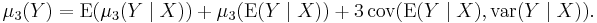
For higher cumulants, a simple and elegant generalization exists. See law of total cumulance.
See also
- Law of total covariance, a generalization
References
- ^ Neil A. Weiss, A Course in Probability, Addison–Wesley, 2005, pages 385–386.
- Billingsley, Patrick (1995). Probability and Measure. New York, NY: John Wiley & Sons, Inc.. ISBN 0-471-00710-2. (Problem 34.10(b))